
[hadoop, spark, AWS] EC2에 하둡 스파크 클러스터 구축하기 - 2
AWS 환경에서 하둡 스파크 클러스터를 구축하는 과정을 기록했다.
1 편에서 이어진다.
1편: https://tes-b.github.io/hadoop/spark/aws/hadoop_spark_on_ec2_1/
3편: https://tes-b.github.io/hadoop/spark/aws/hadoop_spark_on_ec2_3/
인스턴스 이미지 생성
1편에서 설정한 인스턴스를 이미지로 만들어 복사할 것이다.
인스턴스 선택 -> Action -> Create image
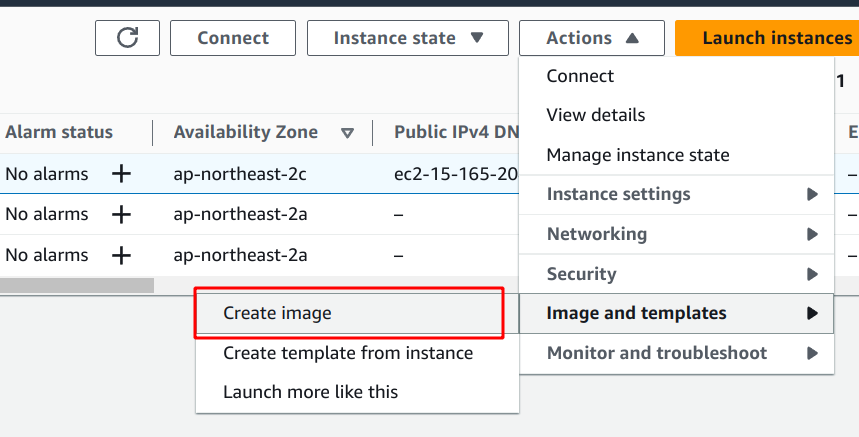
이미지 이름을 원하는 걸로 정해주고
설명은 안써도 상관없는데 나는 하둡 스파크 버전을 적어뒀다.
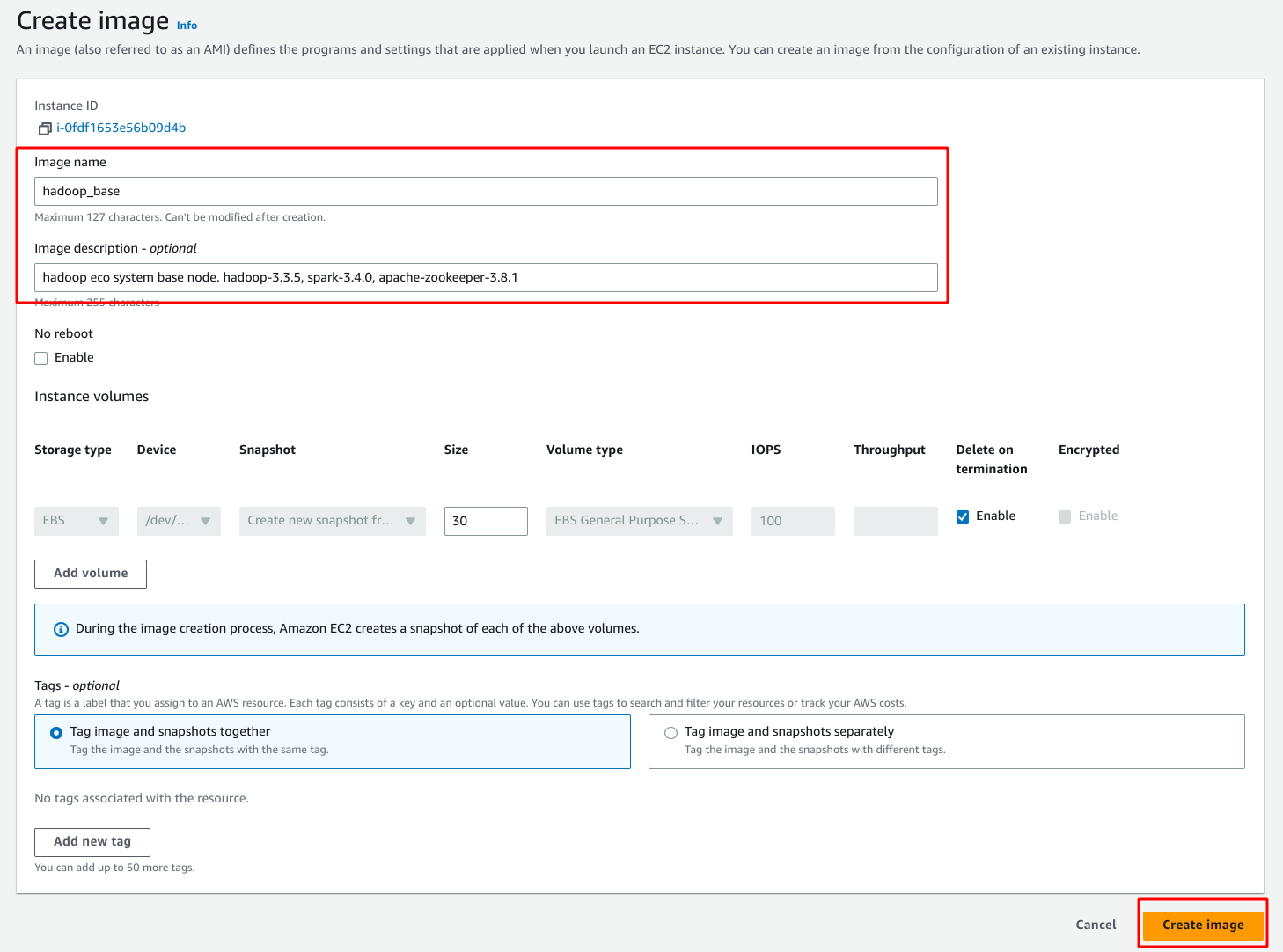
AMIs 메뉴에 들어가서 이미지 이름을 설정한다.
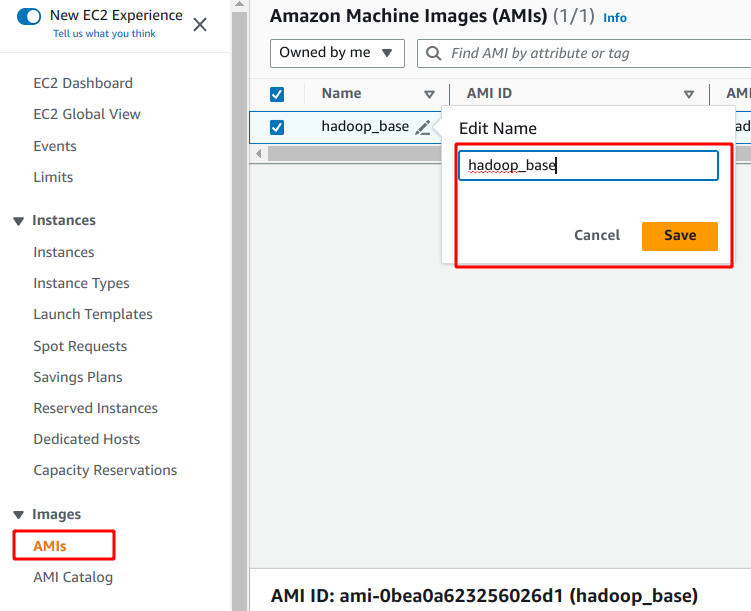
스테이터스가 available 이 되면 사용 할 준비가 되었다는 뜻이다.
이미지로 인스턴스 생성
이미지를 선택하고 Launch instance from AMI로 인스턴스를 생성한다.
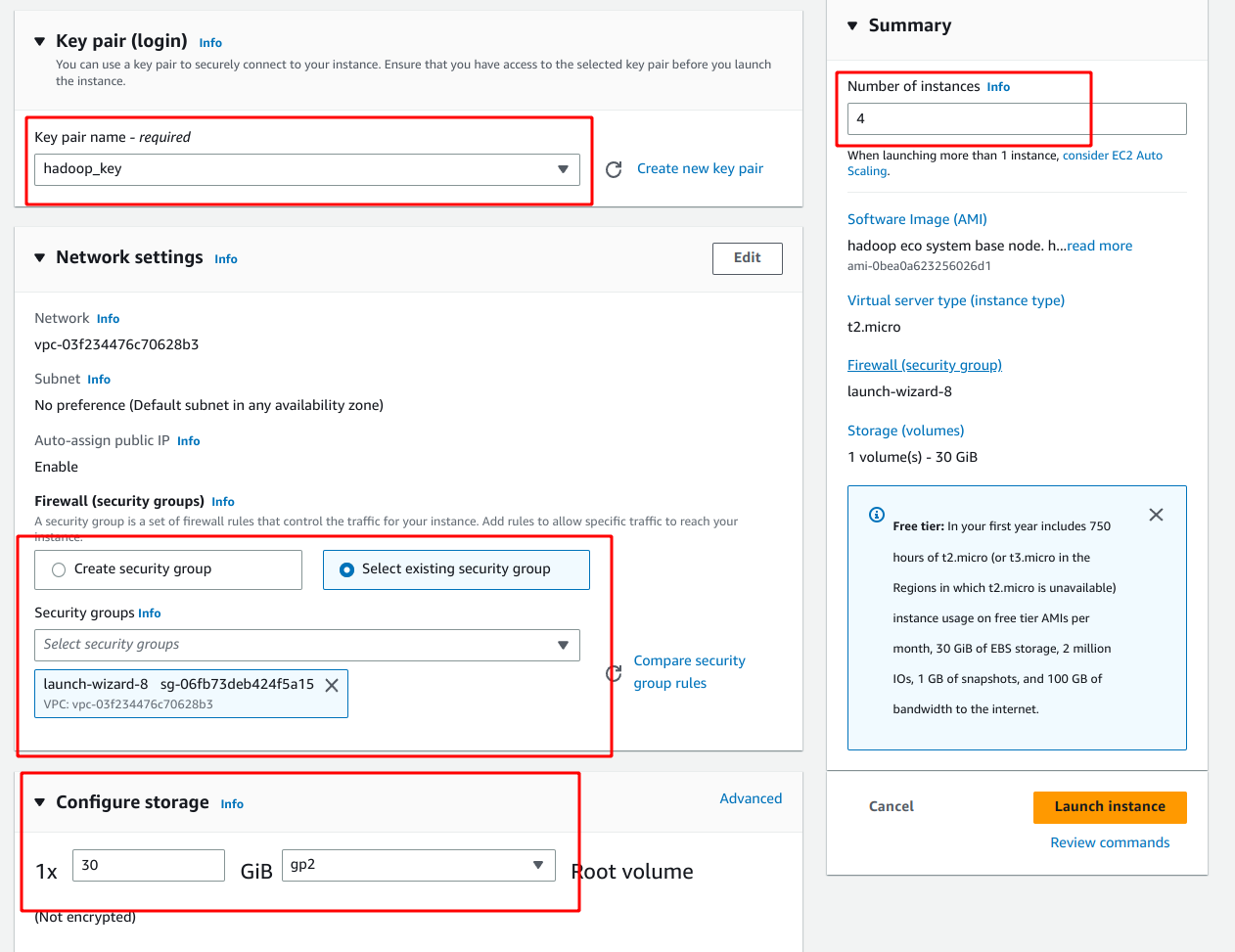
키페어와 보안그룹은 기존인스턴스와 같은걸로 해주는게 편하다.
용량은 넉넉하게 설정하고 인스턴스 4개를 한번에 만들어준다.
인스턴스의 이름을 바꿔준다.
nn1, nn2, dn1, dn2, dn3
nn1 하둡 프라이머리 네임노드면서 스파크 마스터노드가 된다.
nn2은 세컨더리 네임노드로 nn1이 정지할 경우 일을 대신 수행하게 된다.
dn1,2,3은 데이터노드가 될 것이다.
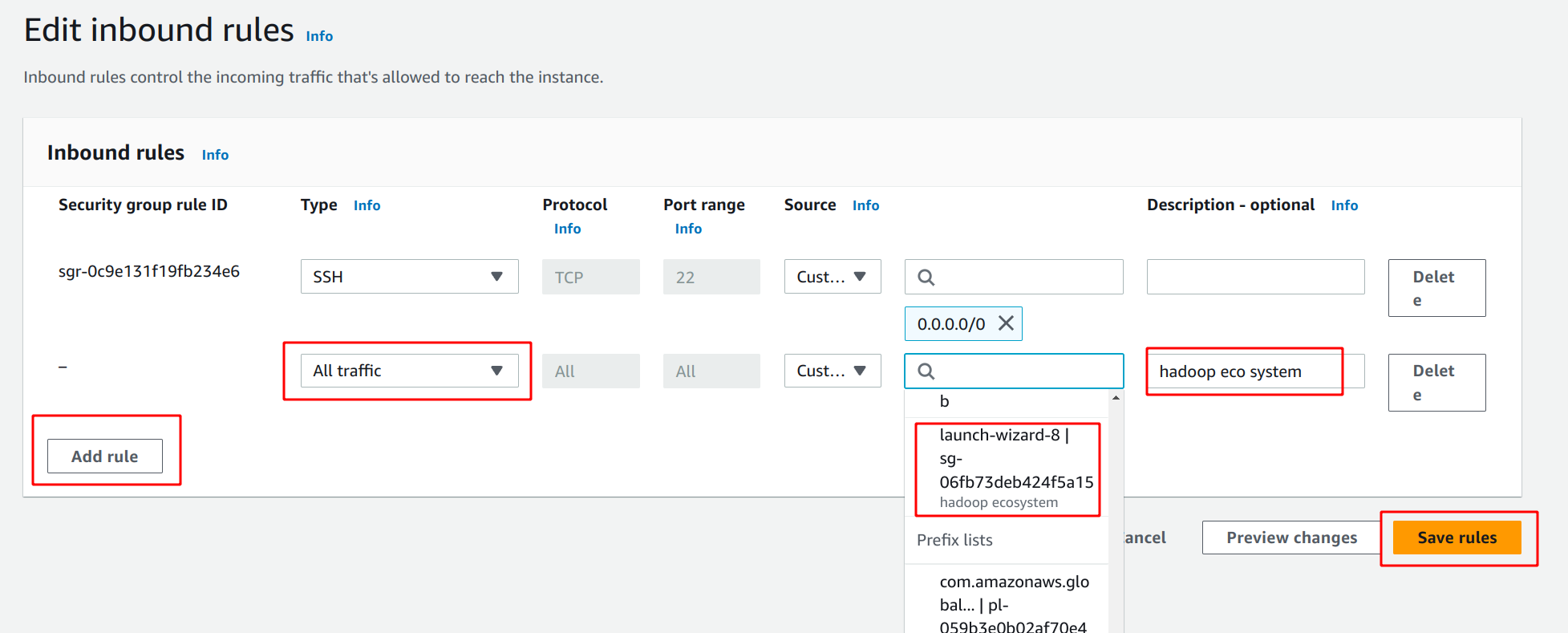
인스턴스 접근 설정
로컬에서 각 노드에 접속하기 편하도록 설정해준다.
cd ~/.ssh
sudo vim config
Host nn1
HostName <네임노드 1번의 public id>
User ubuntu
IdentityFile ~/Documents/key/hadoop_key.pem
Host nn2
HostName <네임노드 2번의 public id>
User ubuntu
IdentityFile ~/Documents/key/hadoop_key.pem
Host dn1
HostName <데이터노드 1번의 public id>
User ubuntu
IdentityFile ~/Documents/key/hadoop_key.pem
Host dn2
HostName <데이터노드 2번의 public id>
User ubuntu
IdentityFile ~/Documents/key/hadoop_key.pem
Host dn3
HostName <데이터노드 3번의 public id>
User ubuntu
IdentityFile ~/Documents/key/hadoop_key.pem
각인스턴스에 접속이 되는지 확인한다.
ssh nn1
ssh nn2
ssh dn1
ssh dn2
ssh dn3
보안그룹 설정
노드들 끼리 서로 ssh로 접속할 수 있게 하기 위해
보안그룹의 인바운드 설정에서 룰을 추가한다.
all traffic에 소스를 현재 보안그룹으로 설정한다.
hosts 편집
지금부터는 각 노드들에서 따로 작업해야 하는 경우가 있어
어떤 노드에서 진행하는지를 nn1 이런식으로 표시할 것이다.
nn1서버로 접속
ssh nn1
nn1
hosts파일 편집
sudo vim /etc/hosts
localhost아래에 추가
public ip가 아닌 private ip를 등록해야 한다.
<네임노드1 private IP> nn1
<네임노드2 private IP> nn2
<데이터노드1 private IP> dn1
<데이터노드2 private IP> dn2
<데이터노드3 private IP> dn3
# /etc/hosts >
172.31.41.146 nn1
172.31.42.199 nn2
172.31.35.251 dn1
172.31.43.180 dn2
172.31.47.37 dn3
이 파일을 다른 노드에 복사해줘야 하는데
현재는 호스트 이름이 ip-xxx-xx-xx-xxx이런 식으로 되어있을 것이다.
이 이름들을 바꿔서 좀더 편하게 접속할수 있게 설정한다.
호스트 이름 설정
sudo hostnamectl set-hostname nn1
재접속 하면 호트트 이름이 반영된다.
같은 방법으로 다른 노드들에 접속해서 전부 이름을 수정해준다.
nn2
sudo hostnamectl set-hostname nn2
dn1
sudo hostnamectl set-hostname dn1
dn2
sudo hostnamectl set-hostname dn2
dn3
sudo hostnamectl set-hostname dn3
다시 nn1 인스턴스에 접속해서 각서버에 파일을 복사해준다.
nn1
cat /etc/hosts | ssh nn2 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn1 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn2 "sudo sh -c 'cat >/etc/hosts'"
cat /etc/hosts | ssh dn3 "sudo sh -c 'cat >/etc/hosts'"
다음은 hdfs-site.xml 파일을 nn2서버로 복사한다.
cat $HADOOP_HOME/etc/hadoop/hdfs-site.xml | ssh nn2 "sudo sh -c 'cat >$HADOOP_HOME/etc/hadoop/hdfs-site.xml'"
각 서버에서 서로 접속이 되는지 확인하고
known_hosts에 등록을 해준다.
ssh <노드이름>
연결이 안되면 진행이 안되기 때문에
꼭 모든 서버에서 각 서버로 접속이 되는지 확인하고 넘어가자.
아래 질문에는 yes를 입력하면 된다.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
여러개의 터미널을 띄울 수 있는 terminator 등을 쓰면 편하게 테스트가 가능하다.
주키퍼 클러스터 설정
주키퍼는 nn1, nn2, dn1서버에서 실행한다.
nn2
nn2에서 주키퍼 아이디를 2로 바꾼다.
sudo vim /usr/local/zookeeper/data/myid
1을 지우고 2로 변경
# /usr/local/zookeeper/data/myid >
2
같은 방법으로 dn1 노드에서 아이디를 3으로 변경.
dn1
sudo vim /usr/local/zookeeper/data/myid
1을 지우고 3로 변경
# /usr/local/zookeeper/data/myid >
3
주키퍼 실행
nn1, nn2, dn1
sudo $ZOOKEEPER_HOME/bin/zkServer.sh start
아래와 같은 메시지가 나오면 성공이다.
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
다음은 상태를 확인한다.
sudo $ZOOKEEPER_HOME/bin/zkServer.sh status
이때 실행 결과를 보면 Mode: follow가 뜨는 서버와
Mode: leader가 뜨는 서버가 있다.
이것은 주키퍼가 랜덤으로 리더를 뽑기 때문에 그렇다고 한다.
하둡 파일 시스템 초기화
nn1 서버에서 파일 시스템을 초기화한다.
nn1
hdfs zkfc -formatZK
처음에 여기서 나는 다음과 같은 에러가 나왔는데
WARNING: /usr/local/hadoop/logs does not exist. Creating.
mkdir: cannot create directory ‘/usr/local/hadoop/logs’: Permission denied
/usr/local/hadoop/logs 경로가 없고 디렉토리를 생성할 권한이 없다고 한다.
모든 노드에서 해당 폴더의 권한설정을 다시 하고 다시 초기화 실행하니 성공했다.
sudo chown -R $USER:$USER /usr/local/hadoop/
hdfs zkfc -formatZK
초기화 확인
nn1
cd /usr/local/zookeeper
주키퍼 쉘 실행
./bin/zkCli.sh
아래처럼 쉘이 실행되면
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
ls /hadoop-ha 명령어를 입력했을 때 [my-hadoop-cluster]라고 출력이 된다면 설정이 된 것이다.
[zk: localhost:2181(CONNECTED) 0] ls /hadoop-ha
[my-hadoop-cluster]
[zk: localhost:2181(CONNECTED) 1]
quit으로 빠져나온다.
저널노드 실행
nn1, nn2, dn1
hdfs --daemon start journalnode
/usr/local/hadoop/logs 디렉터리가 없는경우
WARNING: /usr/local/hadoop/logs does not exist. Creating.
메세지가 출력되고 폴더가 생성된다.
jps 명령어를 입력했을 때 Jps와 JournalNode가 표시되되면
정상적으로 주키퍼 클러스터가 설정이 된 것이다.
하둡 실행
nn1에서 네임노드를 초기화 한다.
nn1
hdfs namenode -format
네임노드 실행
hdfs --daemon start namenode
jps명령을 입력했을 때 NameNode가 나온다면 실행이 된 것이다.
nn2에서도 스탠바이 상태로 네임노드를 실행한다.
nn2
hdfs namenode -bootstrapStandby
다시 nn1으로 돌아가 아래 명령을 실행한다.
nn1
start-dfs.sh
nn1,nn2노드에서 jps실행시
JournalNode와 DFSZKFailoverController 프로세스가 있으면 된 것이다.
이렇게 되어있으면 두 노드중 하나가 죽을 경우 나머지가 네임노드의 일을 수행하게 된다.
얀 실행
nn1 서버에서 실행한다.
nn1
start-yarn.sh
nn1에는 ResourceManager
dn1, dn2, dn3에는 NodeManager가 실행되어있으면 된다.
잡 히스토리 서버 실행
nn1
mapred --daemon start historyserver
jps 해서 JobHistoryServer 실행 확인
네임노드 상태 확인
nn1, nn2
한번에 확인하는 명령어
ubuntu@nn1:~$ hdfs haadmin -getAllServiceState
각각 확인하는 명령어
ubuntu@nn1:~$ hdfs haadmin -getServiceState namenode1
active
ubuntu@nn1:~$ hdfs haadmin -getServiceState namenode2
standby
테스트
모든 프로세스가 잘 실행되었다면
jps를 입력시 다음처럼 나오게 된다.
(nn1에 JobHistoryServer 실행을 깜빡했다.)
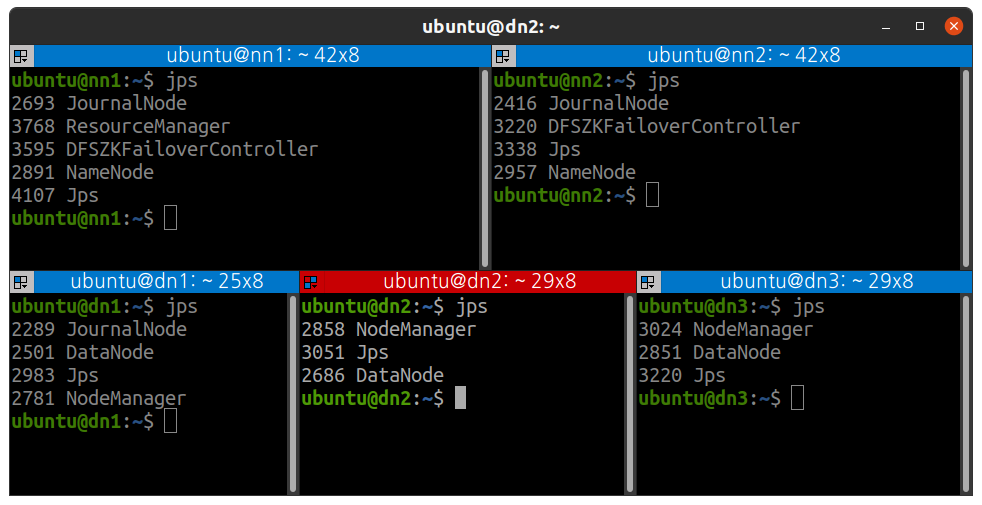
맵리듀스 테스트
맵리듀스 샘플로 워드카운트 기능을 테스트해볼 수 있다.
hdfs dfs -mkdir /test
hdfs dfs -put /usr/local/hadoop/LICENSE.txt /test
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount hdfs:///test/LICENSE.txt /test/output
로그가 출력되고 결과를 확인
hdfs dfs -text /test/output/*
3편에서 계속
3편은 스파크 실행, 웹UI확인, 제플린 설치를 이어서 진행한다.
3편: https://tes-b.github.io/hadoop/spark/aws/hadoop_spark_on_ec2_3/
Leave a comment