
[hadoop, spark, AWS] EC2에 하둡 스파크 클러스터 구축하기 - 3
AWS 환경에서 하둡 스파크 클러스터를 구축하는 과정을 기록했다.
2 편에서 이어진다.
1편: https://tes-b.github.io/hadoop/spark/aws/hadoop_spark_on_ec2_1/
2편: https://tes-b.github.io/hadoop/spark/aws/hadoop_spark_on_ec2_2/
스파크 실행
nn1
$SPARK_HOME/sbin/start-all.sh
정상적으로 실행이 되면 jps 확인시
nn1은 Master, dn1,2,3는 worker라고 나온다.
웹 UI 확인
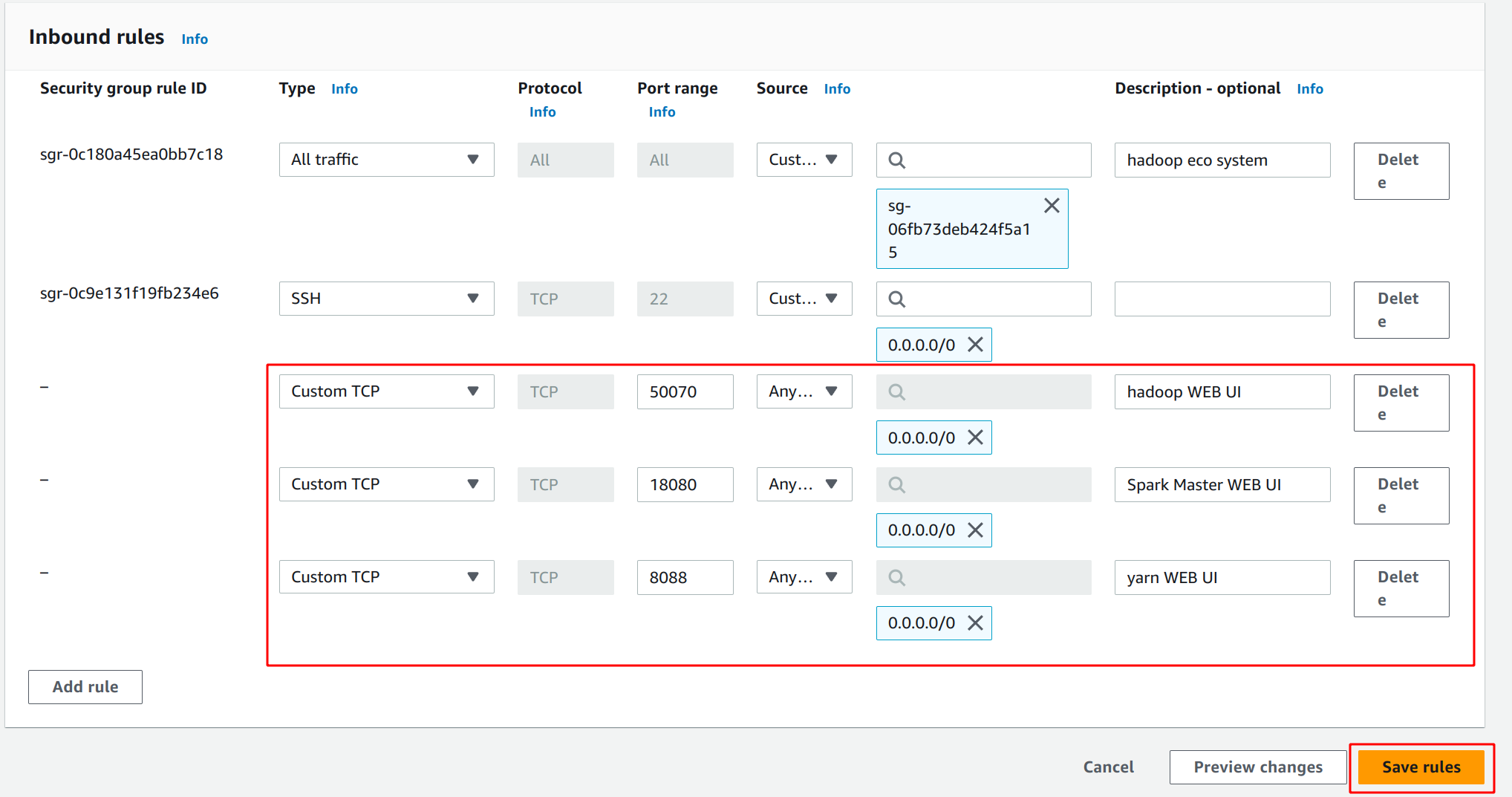
웹 UI에 접속 하기 위해 포트를 열어야 한다.
인바운드 설정에 들어가서
50070, 18080, 8088 포트를 열어준다.
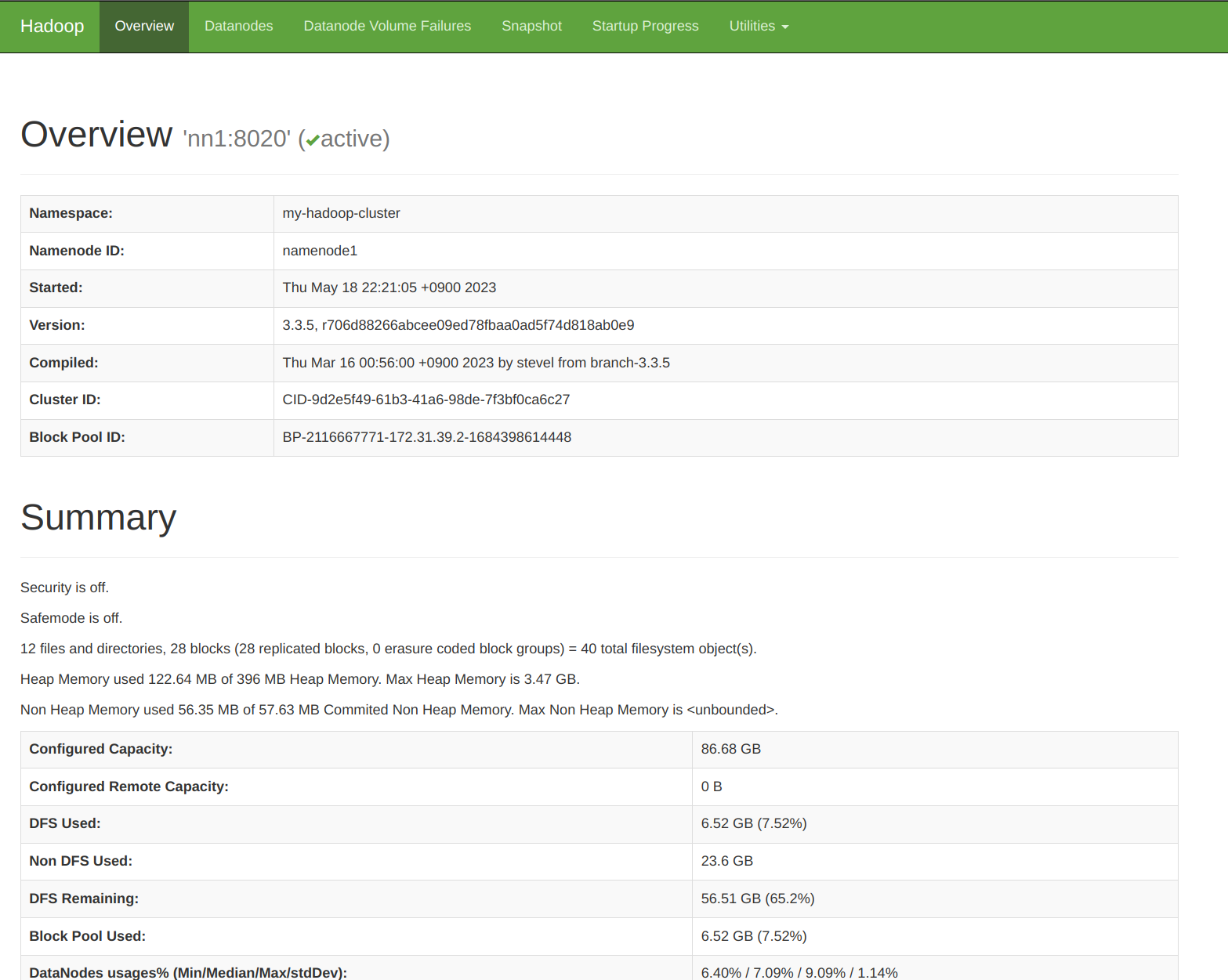
50070 포트는 하둡
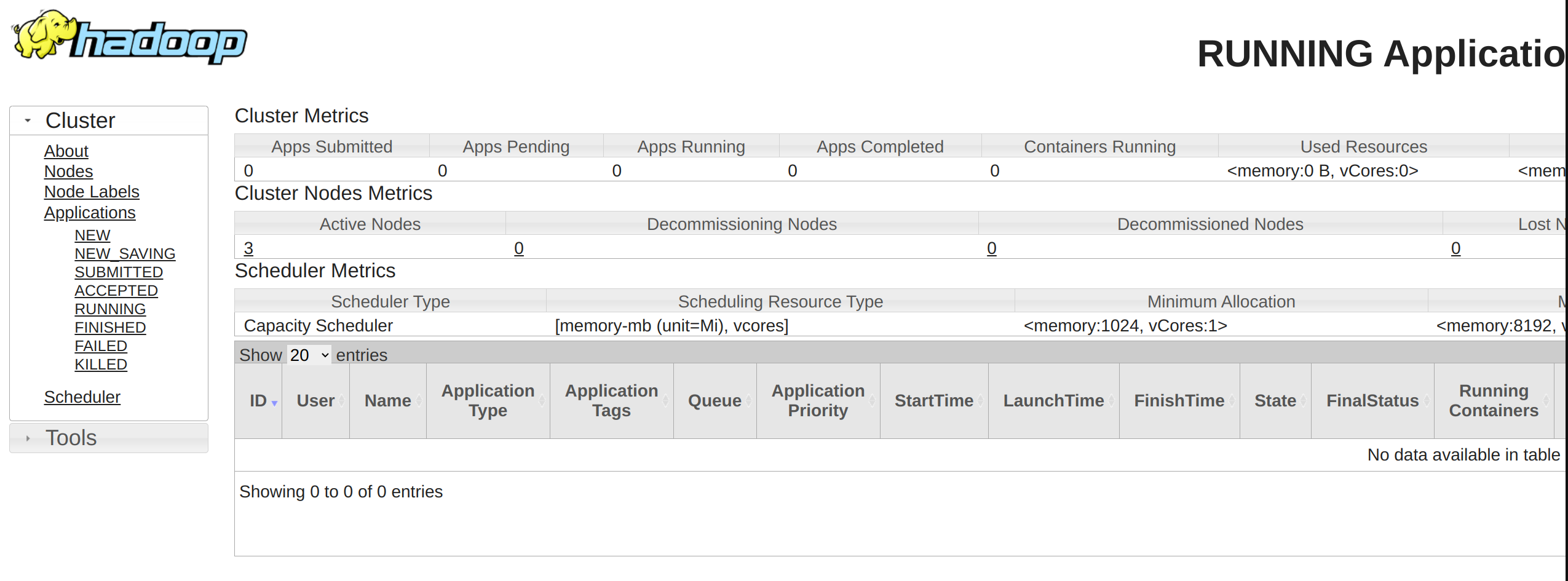
8088 은 얀
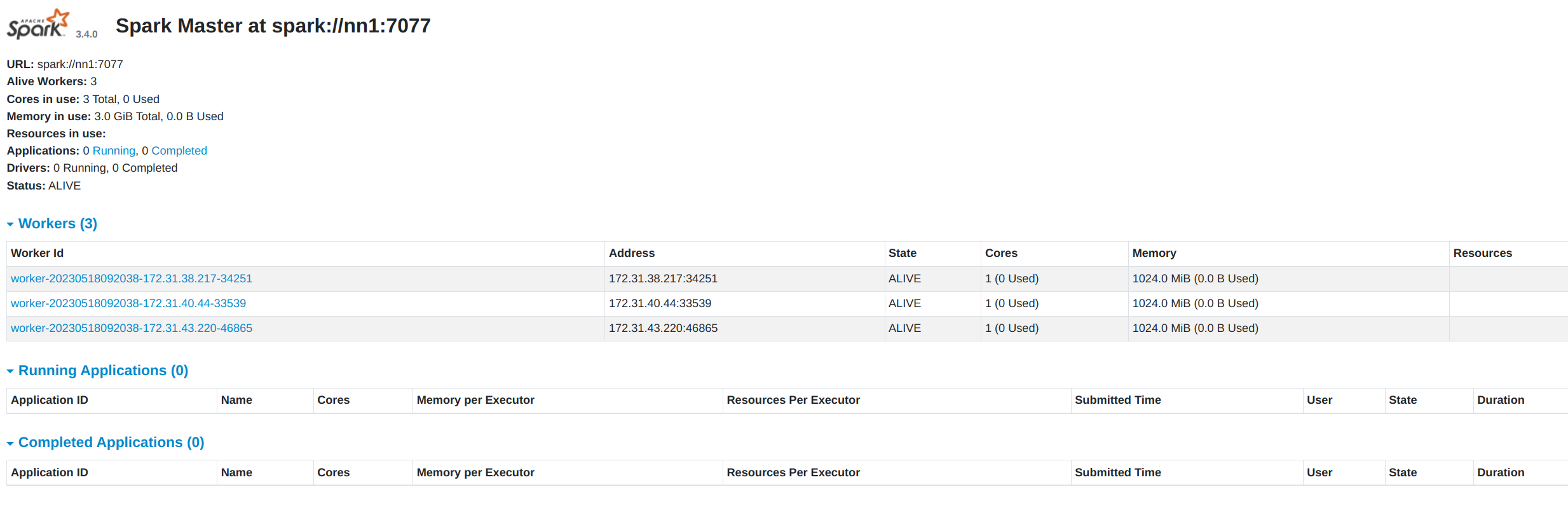
18080은 스파크이다.
하둡 웹UI 접속
http://<nn1 public IP>:50070
얀 웹UI 접속
http://<nn1 public IP>:8088
스파크 웹UI 접속
http://<nn1 public IP>:18080
전체 실행 쉘스크립트 만들기
주키퍼, 하둡, 잡히스토리 서버, 스파크를 한번에 실행/정지 시키는 스크립트를 작성한다.
nn1
전체 실행 스크립트
sudo touch cluster-start-all.sh
# ~/cluster-start-all.sh >
# nn1 Zookeeper Run
sudo /usr/local/zookeeper/bin/zkServer.sh start
# nn2 Zookeeper Run
ssh nn2 "sudo /usr/local/zookeeper/bin/zkServer.sh start"
# dn1 Zookeeper Run
ssh dn1 "sudo /usr/local/zookeeper/bin/zkServer.sh start"
# Hadoop Run
$HADOOP_HOME/sbin/start-all.sh
# Jobhistoryserver Run
mapred --daemon start historyserver
# Spark Run
$SPARK_HOME/sbin/start-all.sh
전체 정지 스크립트
sudo touch cluster-stop-all.sh
# ~/cluster-stop-all.sh >
# Spark Stop
$SPARK_HOME/sbin/stop-all.sh
# Jobhistory Stop
mapred --daemon stop historyserver
# Hadoop Stop
$HADOOP_HOME/sbin/stop-all.sh
전체 재시작 스크립트
sudo touch cluster-restart-all.sh
# ~/cluster-restart-all.sh >
~/cluster-stop-all.sh
~/cluster-start-all.sh
권한설정
sudo chmod 777 cluster*
sudo chown $USER:$USER cluster*
제플린 설치
제플린의 경우 설치 실행은 했지만
스파크와 제플린의 버전이 맞지 않아 파이스파크 연결은 실패했다.
다운로드
sudo wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
압축풀기
sudo tar -zxvf zeppelin-0.10.1-bin-all.tgz -C /usr/local
폴더이름 수정
sudo mv /usr/local/zepellin-0.10.1-bin-all /usr/local/zeppelin
소유권 설정
sudo chown -R $USER:$USER /usr/local/zeppelin/
환경 변수 추가
sudo vim /etc/environment
# /etc/environment >
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/lib/jvm/java-8-openjdk-amd64/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/bin/python3:/usr/local/zeppelin/bin"
JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
HADOOP_HOME="/usr/local/hadoop"
SPARK_HOME="/usr/local/spark"
ZOOKEEPER_HOME="/usr/local/zookeeper"
ZEPPELIN_HOME="/usr/local/zeppelin"
활성화
source /etc/environment
환경변수 추가
sudo echo 'export ZEPPELIN_HOME=/usr/local/zeppelin' >> ~/.bashrc
활성화
source ~/.bashrc
활성화 확인
env | grep ZEPPELIN
설정
cd $ZEPPELIN_HOME/conf
zeppelin-site.xml 파일 수정
cp zeppelin-site.xml.template zeppelin-site.xml
sudo vim zeppelin-site.xml
다음 프로퍼티 값들을
zeppelin.server.addr 값을 0.0.0.0으로 변경.
# $ZEPPELIN_HOME/conf/zeppelin-site.xml >
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
zeppelin.server.port 값은 기본으로 8080으로 되어있는데
원하는 포트로 설정하면 된다.
이번 예시에서는 18888로 변경한다.
# $ZEPPELIN_HOME/conf/zeppelin-site.xml >
<property>
<name>zeppelin.server.port</name>
<value>18888</value>
<description>Server port.</description>
</property>
zeppelin-env.sh 파일 수정
cp zeppelin-env.sh.template zeppelin-env.sh
vim zeppelin-env.sh
# $ZEPPELIN_HOME/conf/zeppelin-env.sh >
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_MASTER=yarn
export ZEPPELIN_PORT=18888
export PYTHONPATH=/urs/bin/python3
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=/usr/bin/python3
제플린 실행
/usr/local/zeppelin/bin/zeppelin-daemon.sh start
실행이 성공하면 아래처럼 나온다.
Zeppelin start [ OK ]
보안그룹 설정
보안그룹 인바운드 설정에서 18888 포트를 열어준다.
접근 가능 아이피는 필요에 따라 설정하면 된다.
이번 예시는 모든 아이피0.0.0.0에서 접근 가능하게 설정했다.
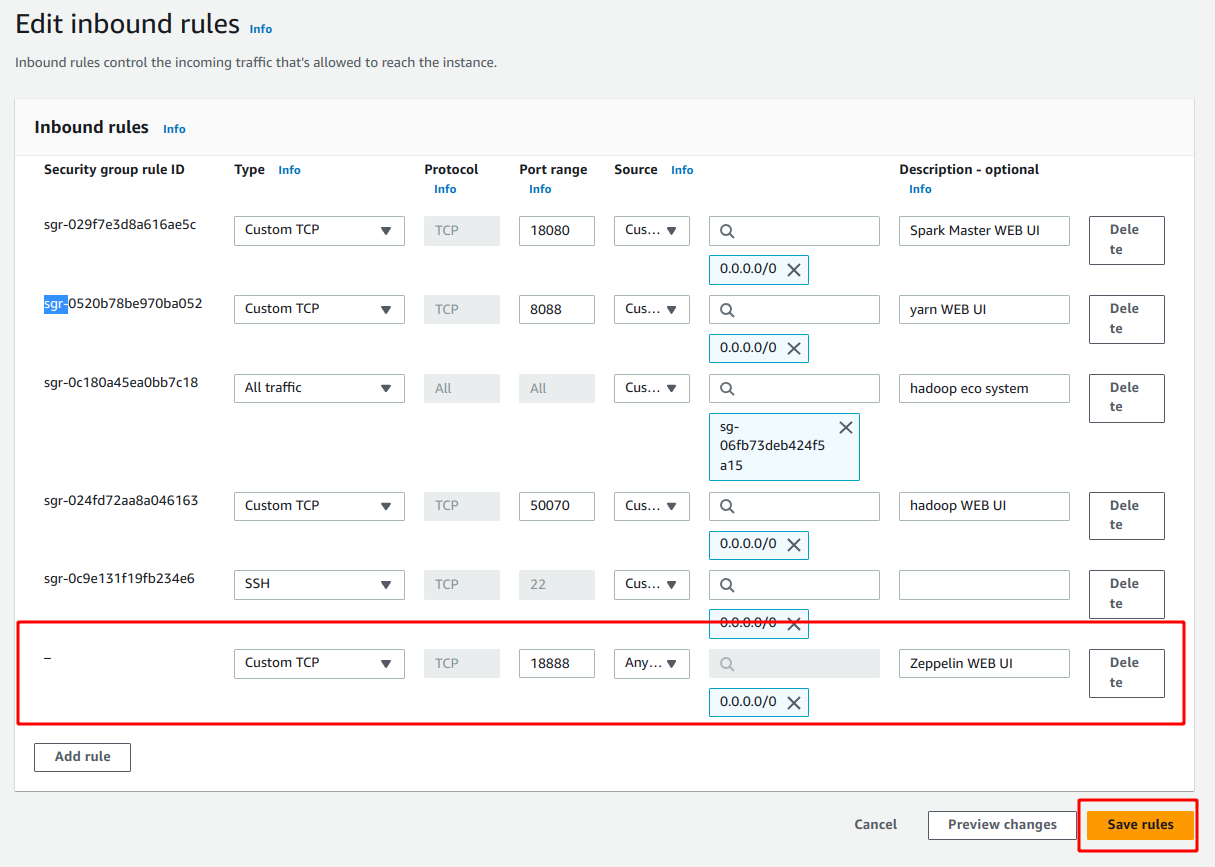
http://<nn1 public IP>:18888로 접속하면 제플린에 접속할 수 있다.
Leave a comment