
[python] Wikipedia API로 크롤러 모듈 제작하기
크롤러를 만들게 된 이유
게임 판매량을 가지고 분석을 진행하는 프로젝트 진행중
데이터에 출시년도 장르 퍼블리셔 등의 항목이 누락되어 있었다.
300개 정도의 항목이 빠져있었는데 일일이 검색해서 채워넣는건
무리라고 판단해 크롤러를 제작해 보기로 마음먹었다.
클래스 만들기
먼저 필요한 모듈들을 임포트했다.
import pandas as pd
from bs4 import BeautifulSoup as bs
import requests
import re
import wikipediaapi
그다음은 클래스와 생성자 작성
생성자에서 위키API 인스턴스를 생성
ExtractFormat은 ‘WIKI’ 와 ‘HTML’ 중 선택이 가능하다.
class WikiCrawler:
def __init__(self):
self.wiki = wikipediaapi.Wikipedia(
'en',
extract_format=wikipediaapi.ExtractFormat.WIKI);
if self.wiki:
print(self.wiki);
함수 작성
다음은 페이지가 존재하는지 확인하고
정보를 담을 딕셔너리를 반환하는 함수 작성
def search_page(self,name):
name_vg = name + " (video game)"; # (video game) 이름뒤에 추가
page = self.wiki.page(name_vg); # 위키에 검색
url = "empty";
dic_values = {
'result' : False,
'msg' : 'unknown',
'year':'unknown',
'genre': 'unknown',
'publisher': 'unknown',
'mode' : 'unknown'};
if page.exists(): # 페이지 존재 확인
url = page.fullurl; # url
else:
page = self.wiki.page(name); # 이름으로 위키 페이지 검색
if page.exists():
if 'game' in page.summary: # 비디오 게임이 맞는지 확인
url = page.fullurl; # url
else :
dic_values['msg'] = 'not a game...'
else:
dic_values['msg'] = 'page not exist'
return dic_values;
현재 목표하는 정보는 위키 우측에 있는 이 박스인데
이부분이 어떤 태그 아래에 있는지 알아내야 했다.
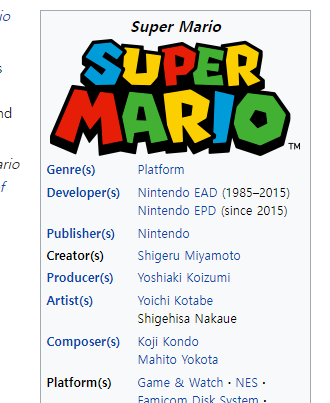
소스코드에서 내용을 검색해보니
저 박스의 이름은 infobox 라는 것을 확인!
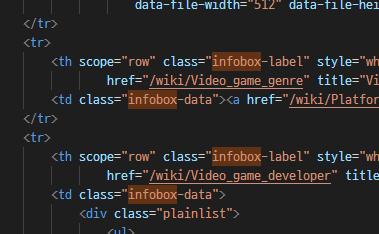 Gotcha!
Gotcha!
클래스명은 infobox 라는것을 알았지만
클래스 내용을 불러오는 방법은 못찾아서
(찾으면 나왔겠지만 일단 되는 방법으로 만드는게 급했다..)
내용들이 tr 태그안에 있는것을 확인하고
tr 태그 안의 내용을 가져와서 키워드로 원하는 정보를 검색하고
뽑아내는 코드를 작성
if tr :
for ele in tr:
if ("Release" in ele.text) & ('year' in values):
list_temp = re.findall(r'\d{4}', ele.text); # 년도
if list_temp:
dic_values['year'] = list_temp[0];
dic_values['result'] = True;
if ("Genre" in ele.text) & ('genre' in values): # 장르
td = ele.find('td');
if td:
list_temp = list(td.stripped_strings); # td 태그 내용
if list_temp:
dic_values['genre'] = list_temp[0];
dic_values['result'] = True;
if ("Publisher" in ele.text) & ('publisher' in values): # 퍼블리셔
td = ele.find('td');
if td:
list_temp = list(td.stripped_strings); # td 태그 내용
if list_temp:
dic_values['publisher'] = list_temp[0];
dic_values['result'] = True;
테스트
 271개의 결측지중 198개를 발견!
271개의 결측지중 198개를 발견!
몇번의 테스트와 예외처리를 거쳐
다소 느리지만 동작하는 크롤러를 완성!
마무리
크롤러를 처음 만들어 보는 점
파이썬 클래스와 모듈을 처음 만들어보는 점
html에 익숙하지 않은점
3가지의 콜라보로 인해
제작에 생각보다 시간이 많이 걸렸다.
그렇지만 역시 안해본걸 해보는게 가장 공부가 많이 되는 것 같다.
프로젝트에 도움이 되어서 만족스럽다.
Leave a comment